Embedding and running Node.js within a Firefox XUL extension
I’m currently working on a little extension for Firefox that discovers and hosts local Node.js game servers across LAN. This entry shows the code behind running a bundled Node.js executable from within the extension.
I'm currently working on a little extension for Firefox that discovers and hosts local Node.js game servers across LAN. This entry shows the code behind running a bundled Node.js executable from within the extension.
I'll be assuming some experience with Firefox extension development, or at least the ability to follow this tutorial.
Being able to run Node.js within a Firefox extension is integral to my concept working. The idea is that anyone with this extension installed will have the ability to run a local Rawkets game server. So how do you run Node.js within an extension then?
Discovering nsIProcess
I didn't know where to start. I'd previously had some experience with bundling NPAPI plugins within a Firefox extension and assumed I'd need to build a plugin to run executable programs like Node.js. Fortunately I was wrong, there is a wonderfully simple interface called nsIProcess that sits within Firefox and allows you to run a binary executable.
nsIProcess has three methods in particular that you'll need; init(), runAsync() and kill(). They allow you to initialise your Node.js process, run it asynchronously, and kill it, respectively.
Bundling the Node.js executable
Before you can run Node.js you need to bundle the executable within your extension. The way you can this is to download and unpack the Node.js source then run the following commands within the terminal:
cd REPLACE_WITH_PATH_TO_THE_NODE_SOURCE_DIRECTORY
./configure
make
Do not run make install as you'll install the executable to your computer and overwrite any version of Node.js that you currently have installed.
Once the make process is complete you'll see a little note in the terminal output that states where the executable was placed. For me this was within the build/default/ directory within the Node.js source you just downloaded and unpacked.
The final step is to create a directory within your extension called components (or whatever else you see fit) and copy the node executable (it's just called node, no extension) from the build/default directory.
Note: You'll probably need to set the unpack flag to true within your install.rdf manifest file to make sure the Node.js executable is unpacked on the user's machine.
Initialising the Node.js process
Now that the Node.js executable is bundled you can set it up within your extension.
Copy the following code within your extension:
(function() {
// Create an nsILocalFile for the Node executable
var file = Components.classes["@mozilla.org/file/local;1"].createInstance(Components.interfaces.nsILocalFile);
file.initWithPath("REPLACE_WITH_ABS_PATH_TO_NODE_EXECUTABLE");
// Check for Node executable
if (!file.exists()) {
// Node executable is missing
return;
};
// Create an nsIProcess to manage the Node executable
var process = Components.classes["@mozilla.org/process/util;1"].createInstance(Components.interfaces.nsIProcess);
process.init(file);
})();
The first line initialises the file variable as an instance of the nsILocalFile interface. You'll be using this to grab the file of the Node.js executable.
On the second line you call the initWithPath() method of nsILocalFile and pass it a string defining the absolute path of the Node.js executable within your plugin.
The following if conditional statement checks to see that the executable was found and actually exists.
Lastly, you set the process variable as an instance of the nsIProcess interface that I mentioned earlier and call the init() method with the executable (referenced via file) as the only argument.
Running and monitoring the process
After initialising the Node.js process you're ready to run it.
Add the following code under process.init(file):
var ObserverHandler = {
// subject refers to the process nsIProcess object
observe: function(subject, topic, data) {
switch (topic) {
// Process has finished running and closed
case "process-finished":
break;
// Process failed to run
case "process-failed":
break;
};
}
};
// Run the Node process and observe for any changes
var args = ["REPLACE_WITH_ABS_PATH_TO_NODE_SCRIPT"];
process.runAsync(args, args.length, ObserverHandler);
There are two things happening here. Let's ignore the ObserverHandler for now and concentrate on the last two lines.
The first of those two lines defines an args variable as an array of strings. This array contains all of the command-line arguments that you want to pass to the Node.js process when you run it. In your case you want to run a Node.js script so just add one string to the array that is the absolute path to a script you've already put together.
The second of the lines calls the runAsync() method of the nsIProcess interface that I described earlier and actually runs the process. The first two arguments passed to this method are the array of arguments you want to pass to the Node.js process and the number of those arguments. The third argument is a nsIObserver interface that will receive notifications about the process, which we'll touch on now.
Your nsIObserver interface is the ObserverHandler object that is defined above the call to runAsync(). It has one method named observe() that is called whenever it receives a notification. This method receives three parameters; subject, topic, and data. They are described in detail on the nsIObserve documentation. For now, you're only interested in the topic parameter.
A simple switch statement checks the topic parameter of any notifications about the process. The only topics available for now are process-finished and process-failed, which occur when the process has finished running and when the process failed to run, respectively.
You won't be using this nsIObserver just yet but it's useful to have here as you'll need it later to deal with issues surrounding the start up and shutdown of the process.
Testing your handiwork
If all went well then you should be able to run your extension and have your Node.js script execcuted by the bundled node executable.
You can check to see if this works by either putting a delay in your Node.js script, or keep it running forever, then checking the Activity Monitor application on OS X (or likewise on other operating systems).
Type "node" into the search bar and you should see a Node.js process running from your extension.
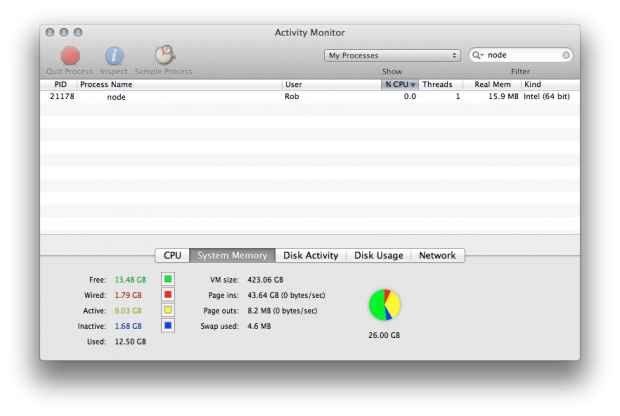
Killing the process
It's all well and good that you've managed to get Node.js running within your extension (yippee!) but it's kind of running forever (not yippee). To fix this you're going to add some functionality that checks for Firefox shutting down and, if so, kills the Node.js process.
Before we continue, you should kill the current Node.js process if it's still running. On OS X you can click on it within the Activity Monitor and then click on the "Quit Process" button at the top left.
The first thing to do is include the Services module by placing the following line above var file, right at the top of your extension:
// Import Services module (startup and shutdown events)
Components.utils.import("resource://gre/modules/Services.jsm");
This module gives you access to a whole bunch of functionality, however all you're interested in at the moment is it's obs property that acts as a reference to the nsIObserverService interface.
Add the following code to the bottom of the extension, just below the call to runAsync():
Services.obs.addObserver(ObserverHandler, "quit-application-granted", false);
This will add a listener for the quit-application-granted event (that is fired just before Firefox closes) and will use the ObserverHandler object you created earlier to handle it.
Finally, add the quit-application-granted handler to the ObserverHandler switch statement and set it to run the kill() method of the Node.js process:
var ObserverHandler = {
// subject refers to the process nsIProcess object
observe: function(subject, topic, data) {
switch (topic) {
// Process has finished running and closed
case "process-finished":
break;
// Process failed to run
case "process-failed":
break;
case "quit-application-granted":
// Shut down any Node.js processes
process.kill();
break;
};
}
};
This will kill the process when Firefox quits. I wouldn't rely on this to kill the process all the time as it won't run if the browser crashes (as if) or if the extension is uninstalled. I'll let you add in that extra functionality.
Testing it all one last time
Now if you run Firefox the Node.js process will be created (yippee!) and if you quit Firefox the process will be killed (double yippee!).
If this isn't the case then you have a problem and I would dig around the Error Console (Shift-Cmd+J) to check for obvious issues.
Doing this in Chrome
Please get in touch if you know how to do this within a Chrome extension, I'm yet to look into that and would love to know for future reference.
Working extension and code download
The full code as a working Firefox extension is up on Github. Feel free to download it, fork it, and generally do whatever you want with it.